In der heutigen Ära der Künstlichen Intelligenz (KI) und des maschinellen Lernens (ML) ist die effiziente Verwaltung von Experimenten entscheidend für den Erfolg von Projekten. KI-Systeme durchlaufen oft zahlreiche Iterationen, in denen verschiedene Modelle und Hyperparameter getestet werden. Ohne geeignete Werkzeuge kann dieser Prozess schnell unübersichtlich werden. Hier setzt Weights & Biases (WandB) an, eine Plattform, die den gesamten ML-Lebenszyklus unterstützt. Sie bietet Funktionen wie Experiment-Tracking, Visualisierungen und Modellmanagement, um Entwicklern und Teams gleichermaßen zu helfen, ihre Projekte effizienter zu gestalten.
Dieser Beitrag erklärt, was WandB ist, welche Vorteile es bietet und wie es in der Praxis verwendet werden kann. Zusätzlich werden Beispiele in Python vorgestellt, um den Einstieg zu erleichtern.
Warum Weights & Biases für KI-Projekte sinnvoll ist
Weights & Biases hebt sich durch seine Vielseitigkeit und einfache Bedienung hervor. Es integriert sich nahtlos in Frameworks wie TensorFlow, PyTorch und scikit-learn. Zu den Hauptvorteilen gehören:
Effizientes Experiment-Tracking: Hyperparameter, Metriken und Ergebnisse werden automatisiert protokolliert.
Visualisierung von Fortschritten: Interaktive Dashboards erleichtern die Analyse von Trainingsverläufen und helfen, Probleme frühzeitig zu identifizieren.
Verbesserte Zusammenarbeit: Ergebnisse und Berichte können unkompliziert im Team geteilt werden, sodass alle Beteiligten den gleichen Informationsstand haben.
Reproduzierbarkeit sichern: Alle relevanten Daten werden dokumentiert, sodass Experimente jederzeit nachvollzogen werden können.
Nahtlose Integration: WandB lässt sich in verschiedene Workflows einbinden, ohne den Entwicklungsprozess zu verlangsamen.
Beispiel in Python mit TensorFlow
Um WandB zu nutzen, muss zunächst das Python-Paket installiert werden:
pip install wandb
Dieses Beispiel zeigt die Integration von WandB in ein TensorFlow-Projekt zur Bildklassifikation mit dem MNIST-Datensatz:
import wandb
from wandb.integration.keras import WandbMetricsLogger, WandbModelCheckpoint
import tensorflow as tf
from tensorflow.keras import layers, models
# WandB initialisieren
wandb.init(project="mnist-tensorflow-example")
# Hyperparameter definieren
config = wandb.config
config.batch_size = 64
config.epochs = 5
config.learning_rate = 0.001
# Daten laden
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
train_images = train_images / 255.0
test_images = test_images / 255.0
# Modell definieren
model = models.Sequential([
layers.Input(shape=(28, 28)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=config.learning_rate),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Training mit WandB Callbacks
model.fit(train_images, train_labels,
validation_data=(test_images, test_labels),
epochs=config.epochs,
batch_size=config.batch_size,
callbacks=[
WandbMetricsLogger(),
WandbModelCheckpoint(filepath='model.keras')
])
wandb.finish()
Ohne WandB würden wichtige Informationen über das Training (z. B. Hyperparameter, Metriken oder Modellverläufe) entweder gar nicht oder nur lokal auf der Festplatte gespeichert. Mit WandB hingegen wird Folgendes hinzugefügt, um eine nahtlose Integration zu gewährleisten:
Projektinitialisierung
wandb.init(project="mnist-tensorflow-example") ist der erste Schritt, um WandB zu starten und ein Projekt zu definieren. Dies erstellt automatisch eine Online-Umgebung, in der alle Runs gespeichert werden. Ohne diesen Schritt wären die Ergebnisse nur lokal und für Teammitglieder nicht zugänglich.
Dynamisches Hyperparameter-Management
Durch die Nutzung von wandb.config können Hyperparameter wie batch_size`, epochs oder learning_rate zentralisiert und dokumentiert werden. Diese Parameter können im Dashboard eingesehen und über verschiedene Runs hinweg verglichen werden. Ohne WandB müssten diese Werte manuell verwaltet und in der Regel fest in den Code geschrieben werden.
Automatisches Logging
Die Callbacks WandbMetricsLogger und WandbModelCheckpoint` loggen automatisch Trainingsmetriken wie Verlust und Genauigkeit sowie die Checkpoints des Modells. Dies spart Zeit und reduziert Fehler, da alle relevanten Daten konsistent erfasst werden. Ohne WandB würden diese Informationen häufig in separaten Dateien gespeichert oder müssten manuell aufgezeichnet werden.
Zentrale Speicherung und Visualisierung
Mit WandB werden alle Logs und Ergebnisse automatisch auf der Plattform gespeichert. Dadurch sind sie nicht nur zentral zugänglich, sondern auch visuell aufbereitet. Ohne WandB wären diese Daten nur lokal verfügbar, müssten manuell organisiert werden und wären für andere Teammitglieder schwieriger nachzuvollziehen.
Erweiterte Features: Hyperparameter-Sweeps
Ein weiterer wichtiger Aspekt von WandB ist die Unterstützung von Hyperparameter-Tuning mittels Sweeps. Mit Sweeps können verschiedene Kombinationen von Hyperparametern systematisch getestet werden, um herauszufinden, welche Konfiguration die besten Ergebnisse liefert. Dies ist besonders nützlich in Projekten, bei denen die optimale Modellleistung stark von Hyperparametereinstellungen abhängt, wie z. B. Lernrate, Batch-Größe oder Aktivierungsfunktionen.
Ein Sweep arbeitet, indem er verschiedene Konfigurationen erstellt und für jede Konfiguration eine Reihe von Trainingsläufen (Runs) durchführt. Die Ergebnisse aller Runs werden zentral im WandB-Dashboard gesammelt und visualisiert. Entwickler können dann leicht erkennen, welche Hyperparameter die besten Werte für spezifische Metriken wie Verlust oder Genauigkeit erzielt haben. Hier ein Beispiel:
def train():
wandb.init()
config = wandb.config
# Modell definieren
model = models.Sequential([
layers.Dense(128, activation='relu', input_shape=(28, 28)),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=config.learning_rate),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Daten laden
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
train_images = train_images / 255.0
test_images = test_images / 255.0
model.fit(train_images, train_labels, epochs=5, batch_size=64, callbacks=[WandbCallback()])
sweep_config = {
"method": "grid",
"parameters": {
"learning_rate": {
"values": [0.001, 0.01, 0.1]
}
}
}
sweep_id = wandb.sweep(sweep_config, project="sweep-example")
wandb.agent(sweep_id, train)
Dieses Beispiel zeigt, wie mehrere Kombinationen von Hyperparametern automatisch getestet und protokolliert werden können. Der Code beginnt mit der Definition einer Trainingsfunktion, die von WandB aus mit verschiedenen Hyperparameterkonfigurationen ausgeführt wird.
Zunächst wird ein einfaches Modell mit zwei Schichten definiert, das auf den MNIST-Datensatz trainiert wird. Die Lernrate wird dynamisch basierend auf der aktuellen Konfiguration („config“) festgelegt, die von WandB vorgegeben wird. Während des Trainingsprozesses loggt WandB automatisch die Verluste und Genauigkeitsmetriken für jede Epoche.
Die Sweep-Konfiguration wird mit der Methode „grid“ festgelegt, die alle möglichen Kombinationen der angegebenen Werte für die Lernrate durchprobiert. In diesem Fall werden drei Werte getestet: 0.001, 0.01 und 0.1. WandB generiert basierend auf dieser Konfiguration automatisch alle erforderlichen Runs und startet sie nacheinander mit dem wandb.agent Befehl.
Die WandB-Benutzeroberfläche: Dashboards und Panels
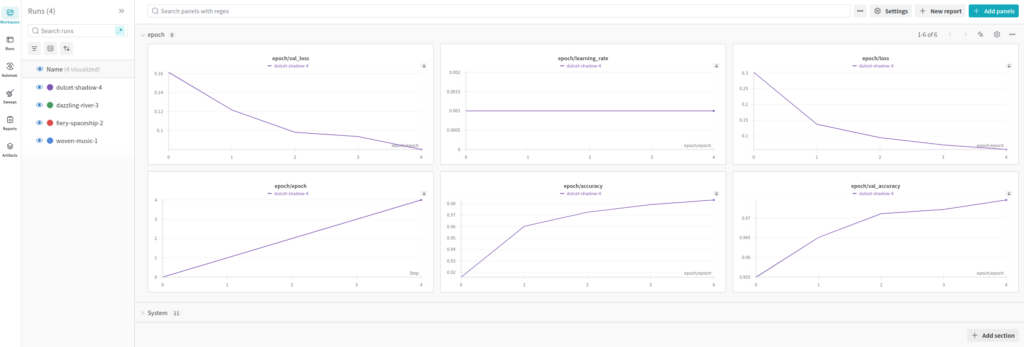
Das Dashboard visualisiert die Ergebnisse jeder Kombination, sodass Entwickler leicht erkennen können, welche Konfiguration die besten Ergebnisse liefert. Zusätzlich bietet WandB detaillierte Diagramme, die den Verlauf der Metriken für jede Hyperparameter-Einstellung zeigen. Dies erleichtert die Identifikation von Mustern oder unerwarteten Verhalten während des Trainings.
Ein großer Vorteil von WandB ist die benutzerfreundliche Oberfläche, die Entwicklern detaillierte Einblicke in ihre Experimente bietet. Die Dashboards enthalten interaktive Panels, die eine Vielzahl von Informationen darstellen:
Run-Übersicht: Eine Liste aller Experimente (Runs), die in einem Projekt durchgeführt wurden, inklusive Metriken wie Verlust und Genauigkeit.
Trainingskurven: Graphen, die den Verlauf von Metriken wie Verlust und Genauigkeit über die Epochen hinweg anzeigen.
Vergleiche: Tools, um mehrere Runs miteinander zu vergleichen, inklusive Visualisierungen von Hyperparametern.
Hyperparameter-Suche: Ergebnisse von Sweeps, die optimale Kombinationen von Hyperparametern darstellen
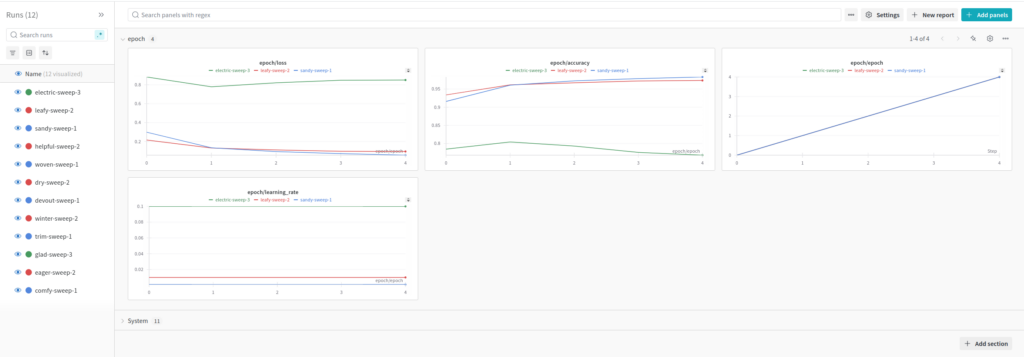
Der Screenshot zeigt ein typisches WandB-Dashboard mit einer interaktiven Benutzeroberfläche. Links findet sich die Run-Übersicht, die alle Experimente eines Projekts auflistet, inklusive Metriken wie Verlust und Genauigkeit. Im Hauptbereich werden Trainingskurven angezeigt, die den Verlauf von Metriken wie Verlust über die Epochen hinweg visualisieren. Unten sind Panels für Hyperparameter, Vergleichstools und zusätzliche Notizen sichtbar. Diese Oberfläche ermöglicht es, Daten effektiv zu analysieren und direkt zu vergleichen.
Die Vorteile von WandB
Die Nutzung von WandB bringt zahlreiche Vorteile, die den Workflow und die Effizienz in KI-Projekten erheblich verbessern können. Zum einen spart das automatische Logging Zeit, da manuelle Aufzeichnungen von Metriken oder Hyperparametern entfallen. Entwickler müssen sich nicht mehr darum kümmern, Werte manuell festzuhalten, sondern können sich voll auf die Optimierung des Modells konzentrieren.
Ein weiterer Vorteil ist die systematische Modellübersicht. WandB visualisiert die Trainingskurven und Metriken wie Verlust oder Genauigkeit übersichtlich in interaktiven Dashboards. Diese erleichtern es, Fehlerquellen zu identifizieren oder Optimierungspotenziale aufzudecken. Die Verfügbarkeit dieser Daten in Echtzeit macht den Entwicklungsprozess effizienter.
Zusätzlich verbessert WandB die Teamarbeit erheblich. Die Plattform bietet eine gemeinsame Umgebung, in der alle Teammitglieder auf Ergebnisse zugreifen, Runs vergleichen und Berichte teilen können. Diese zentralisierte Organisation reduziert Kommunikationsaufwand und sorgt dafür, dass alle Beteiligten auf dem gleichen Stand bleiben.
WandB ist außerdem flexibel anpassbar und lässt sich in viele verschiedene Workflows und Frameworks integrieren. Das macht es sowohl für kleine Projekte als auch für große Teamprojekte geeignet. Für Einzelanwender oder kleinere Teams steht eine kostenfreie Version zur Verfügung, die dennoch die meisten wichtigen Funktionen bietet.
Hilfreich ist die Hyperparameter-Sweep-Funktion. Sie ermöglicht es, verschiedene Kombinationen von Hyperparametern systematisch zu testen und die besten Einstellungen für ein Modell zu finden. Dies spart Zeit und liefert strukturierte Ergebnisse, die für die Optimierung von Modellen unverzichtbar sind.
Lerneffekte und Tipps
Einige Aspekte, die beim Einsatz von WandB beachtet werden sollten:
Konsistente Benennung von Runs: Klare Namen erleichtern die Organisation.
Tags und Notizen verwenden: Tags helfen, ähnliche Experimente zu gruppieren.
Automatische Speicherung aktivieren: Checkpoints können automatisch gespeichert werden.
Reports für Präsentationen nutzen: Ergebnisse können anschaulich dokumentiert werden.
Hyperparameter-Sweeps gezielt einsetzen: Sweeps bieten große Möglichkeiten, können aber zeitaufwändig sein. Klare Zielsetzungen sind hier wichtig.
Abschließender Blick: WandB im Kontext der KI-Entwicklung
Weights & Biases bietet eine umfassende Plattform, die sich ideal zur Optimierung von KI-Prozessen eignet. Von der Nachverfolgung und Dokumentation von Experimenten bis hin zur Visualisierung und Analyse von Ergebnissen erleichtert es die Arbeit von Entwicklern und Teams erheblich. Ein zentraler Vorteil von WandB ist die automatische Protokollierung von Hyperparametern, Metriken und Modellergebnissen, die sonst manuell erfasst werden müssten. Die intuitive Benutzeroberfläche stellt diese Daten in Echtzeit bereit und ermöglicht einen direkten Vergleich von Experimenten. Dies spart nicht nur Zeit, sondern bietet auch Einblicke, die zur Verbesserung der Modellleistung genutzt werden können.
Die Hyperparameter-Sweep-Funktion ist ein weiteres Feature, das es erlaubt, verschiedene Kombinationen von Hyperparametern systematisch zu testen. Entwickler können so die optimale Konfiguration effizient ermitteln, ohne dabei wertvolle Ressourcen zu verschwenden. WandB’s Möglichkeit, alle Runs zentral zu speichern und in interaktiven Dashboards zu visualisieren, verbessert zudem die Reproduzierbarkeit von Ergebnissen. Die Plattform ist flexibel in bestehende Workflows integrierbar und eignet sich sowohl für Einzelentwickler als auch für große Teams.
Obwohl eine kurze Einarbeitung erforderlich ist, zahlt sich der Einsatz von WandB durch den langfristigen Effizienzgewinn aus. Die erweiterte Funktionalität, wie z. B. die Teamkollaboration und das Teilen von Berichten, machen es zu einem nützlichem Werkzeug für moderne ML-Workflows.
- Datenanalyse, KI, Python, Weights & Biases











